
摘要:近日,国家纳米科学中心赵宇亮院士团队系统综述了机器学习模型在预测无机纳米颗粒毒性方面的最新进展。首先阐述了纳米毒性的作用机制(如氧化应激、细胞膜损伤等)及其影响因素(包括纳米颗粒的物理化学性质、细胞类型和暴露条件等)。接着,回顾了经典的纳米毒性预测统计模型(如nanoQSAR、PBPK和MA模型),并重点探讨了机器学习加速的相应模型(ML–nanoQSAR、ML–PBPK和ML–MA)的发展,详细介绍了所用算法、模型构建方案、预测性能及关键特征。此外,还介绍了一些重要的纳米毒性数据库,为未来模型开发提供数据支持。尽管已取得显著进展,但构建高效、稳健且可解释的机器学习预测模型仍面临数据质量不一、模型整合不足等挑战。未来需进一步开展跨学科合作,结合多组学数据与新兴信息技术,推动纳米毒性评估向更精准、可持续的方向发展。
背景介绍:
随着纳米技术的发展,无机纳米颗粒在生物医学、环境化学和材料科学等领域展现出巨大的应用潜力。然而,其在疾病治疗或环境暴露过程中可能对正常生物系统产生细胞毒性,引发了对其安全性的广泛关注。为确保纳米颗粒的可持续应用,开发高效的毒性预测与风险评估策略显得尤为重要。传统上,研究者已建立包括纳米定量结构-活性关系、生理药代动力学模型和元分析在内的统计模型来预测纳米毒性,但这些模型往往受限于数据质量、个体差异和研究异质性,预测能力有限。近年来,机器学习的快速发展为处理高维数据、识别复杂模式、优化模型性能提供了新的途径,极大地推动了纳米毒性预测模型的精准化与智能化发展。
本文亮点:
本文首先阐述了纳米材料细胞毒性的各种机制,详细介绍了氧化应激、细胞膜损伤等以及各机制的相互联系,并全面总结了影响细胞毒性的因素,涵盖纳米颗粒的物理化学性质、细胞类型与状态、暴露剂量与时间及生物环境等。
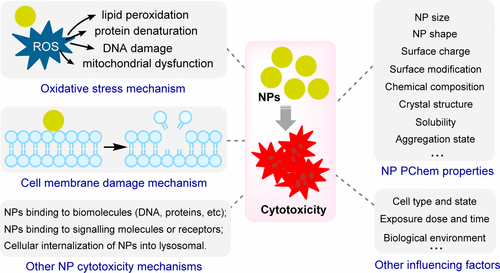
图1.实验报道的纳米材料细胞毒性机制和影响因素
随后系统介绍了纳米定量构效关系(nanoQSAR)、生理药代动力学(PBPK)和荟萃分析(MA)三种经典纳米材料毒性预测模型。利用大量不同研究团队开发的nanoQSAR模型和PBPK模型,展示了各模型的应用效果与优势,如nanoQSAR模型建立物理化学性质与生物活性的定量关系,PBPK模型模拟纳米颗粒在体内的ADME过程,同时也指出了模型对实验数据的依赖和统计误差等局限性。
接下来,本文深入探讨了机器学习算法在纳米毒性预测中的应用,包括监督学习、无监督学习和集成学习算法,这些算法能够处理大规模高维数据,快速识别复杂模式,大幅提升模型的预测准确性和泛化能力。通过与传统统计模型对比,凸显其在预测性能上的优势,不仅能更准确预测毒性,还能识别关键影响因素。此外,还规范了机器学习加速模型的开发流程,涵盖数据收集、特征提取、模型训练和验证等步骤,为研究人员提供清晰指导。
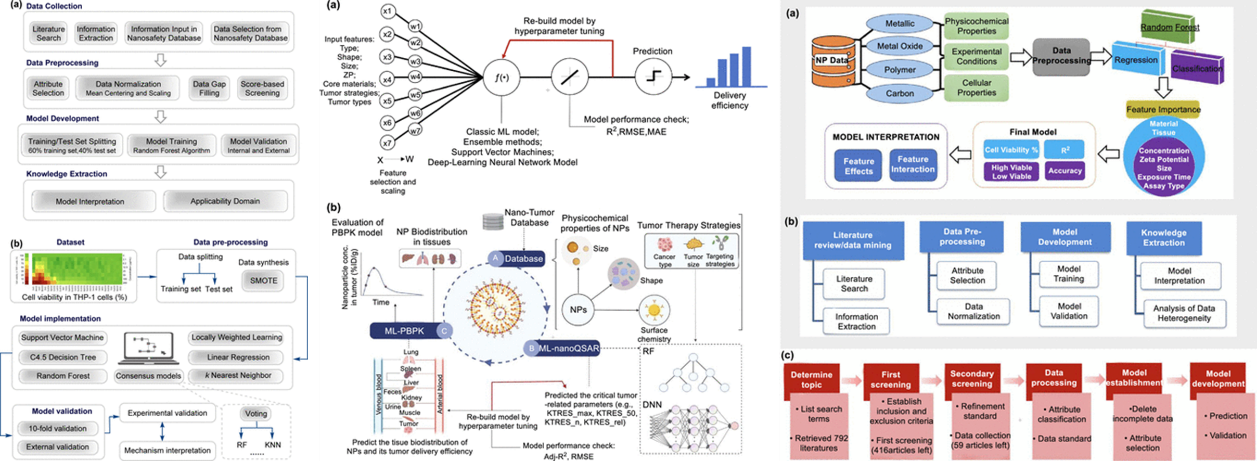
图2. 用于开发 ML模型的工作流程
最后,本文介绍了eNanoMapper、NKB、NanoSolveIT等重要的纳米材料毒性数据库,它们整合了纳米颗粒的物理化学性质、生物效应、实验方法等多方面数据,为研究提供丰富资源。数据库在数据质量控制和可用性方面遵循FAIR原则,确保数据数量庞大且质量可靠,可有效支持机器学习模型的训练和验证。这些数据库大多由国际知名科研项目或机构支持开发,具有较高的权威性和国际影响力,促进了全球范围内的纳米材料毒性研究合作与发展。
总结与展望:
本研究全面回顾了纳米材料细胞毒性的机制、影响因素、预测模型及数据库。介绍了细胞毒性机制及其影响因素,还探讨了三种经典统计预测模型及对应的机器学习加速模型,包括算法、优势、开发方案及预测性能等。尽管在预测和评估纳米材料的细胞毒性和风险方面取得了许多突破,但仍面临诸多的挑战:一是数据问题,数据质量不一、缺失、格式差异等,需建大规模高质量数据库;二是建模问题,复杂模型可解释性差,多模型整合困难,需开发针对有限数据的算法;三是其他问题,理论计算不足,需多学科合作,建立合理的合作模式。最后,作者呼吁基于多组学和新兴信息技术开发预测模型。
文章详情:
Recent Advances in Machine Learning Models for Predicting Toxicity of Inorganic Nanoparticles
Mingli Li, Qiao-Zhi Li*, Yuliang Zhao, and Xingfa Gao*
Cite this by DOI: 10.1021/cbe.5c00048
文章链接:https://doi.org/10.1021/cbe.5c00048

